저번 글에 이어서 계속 책 내용을 진행해 보려고 한다
상대 URL을 절대 URL로 변경
- 페이지에서 링크를 추출하는 프로그램을 저번에 작성하였는데, a 태그의 href 속성을 잘 살펴보면
절대 경로가 아닌 상대경로로 출력되던 것을 알 수 있었다
- 상대경로란, 현재 웹 페이지의 위치를 기준으로 기술한 대상 파일의 경로를 뜻하는데
- Node.js의 'url' 표준 module을 사용하면 상대경로를 절대 경로로 변환할 수 있다.
- url 모듈의 resolve 메소드를 사용한다 (parameter로 기본 url과, 상대 url을 인자로 준다)
- 코드
// download url module
const urlType = require('url');
// convert relative path to absolute path
const base = "http://kujirahand.com/url/test/index.html";
let u1 = urlType.resolve(base, 'a.html');
console.log(`u1 = ${u1}`);
let u2 = urlType.resolve(base, '../b.html');
console.log(`u2 = ${u2}`);
let u3 = urlType.resolve(base, '/c.html');
console.log(`u3 = ${u3}`);
- 결과

- 이러한 reslove() 메소드를 사용하여 앞에 글에서 작성한 showlink.js를 개선해 본다면
- 코드
// download modules
const client = require('cheerio-httpcli');
const urlType = require('url');
// url and params
const url = "http://jpub.tistory.com";
let param = {};
// download from url
client.fetch(url, param, function(err, $, res) {
if(err) {console.log("error"); return;}
// print as extract link
$("a").each(function(idx){
let text = $(this).text();
let href = $(this).attr('href');
if(!href) return;
// convert relative path to absolute path
let href2 = urlType.resolve(url, href);
// print result
console.log(`text ${href}`);
console.log(`=> ${href2}\n`);
});
});
- 결과

이미지 파일 추출
- 이번에는 페이지에 삽입된 이미지 파일의 URL 목록을 추출하는 프로그램을 작성할 것이다.
- 코드
// loading modules
const client = require('cheerio-httpcli');
const urlType = require('url');
// downloading
const url = `https://ko.wikipedia.org/wiki/${encodeURIComponent("강아지")}`;
let param = {};
client.fetch(url, param, function(err, $, res) {
if(err) {console.log("error"); return;}
// print as extract links
$("img").each(function(idx) {
let src = $(this).attr('src');
src = urlType.resolve(url, src);
console.log(src);
})
})
- 결과
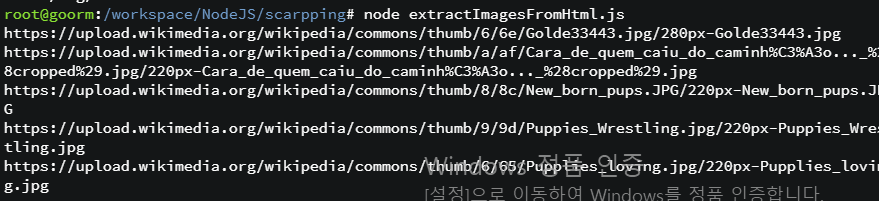
- 이어서 추출한 URL 이미지 파일을 다운로드하는 프로그램을 만들어 볼 것이다.
- 코드
// loading modules
const request = require('request');
const client = require('cheerio-httpcli');
const urlType = require('url');
const fs = require('fs')
// assigned path will be saved.
const savedir = __dirname + "/img";
// if the path no exists, create a new path.
if(!fs.existsSync(savedir)) {
fs.mkdirSync(savedir);
}
// assign path
const url = `https://ko.wikipedia.org/wiki/${encodeURIComponent("강아지")}`;
let param = {};
// get a file
client.fetch(url, param, function(err, $, res) {
if(err) {console.log("error"); return;}
// print as extract links
$("img").each(function(idx) {
let src = $(this).attr('src');
src = urlType.resolve(url, src);
// console.log(src);
// naming save file
let fname = urlType.parse(src).pathname;
fname = savedir + "/" + fname.replace(/[^a-zA-Z0-9\.]+/g, '_');
// downloading
request(src).pipe(fs.createWriteStream(fname));
})
})
- 결과
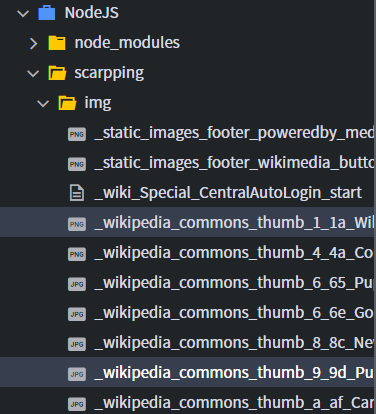
- 위 프로그램에서는, 위키피디아의 강아지 페이지에 있는 이미지 파일들을, img 디렉토리를 만들고
그곳에 이미지를 다운로드하게한다.
- 그러기 위해서, fs.mkdirSync() 메소드를 사용하여 디렉토리를 생성하였는데, 메소드의 인자로 경로를 받는다.
- Node.js에서는 스크립트의 실행 디렉토리가 '__dirname'이라는 변수에 담겨있어, 이 변수를 참조함으로써
쉽게 저장 경로를 저장할 수 있었다.
- fs.mkdir() 메소드가 존재하지만, 이 메소드는 비동기적으로 동작한다. 예를 들어,
파일이나 디렉토리의 작성 완료된 시점에서 두 번째 인자로 지정한 콜백함수가 호출되는 반면에
fs.mkdirSync() 메소드는 디렉토리의 작성이 완료될때까지 스크립트의 흐름을 멈추고 대기한다.
- 이후에는, HTML 파일을 취득하고 <img> 태그 목록을 얻어온 후, 각 요소에 대해서 다운로드 처리를
수행한다.
- 저장할 파일 이름을 정하기 위해 URL에서 경로명을 추출하고, 추출한 경로명에서 알파벳과 숫자,
도트 이외의 문자를 '_'로 변환한 것을 볼 수 있다
- 마지막으로 request 모듈을 사용하여 다운로드를 수행하였다.
사이트를 통째로 다운로드
- 통째로 다운로드하는 이유 :
- 오프라인 상태에서도 사이트를 볼 수 있다.
- 로컬에 HTML을 다운로드하고 쉽게 검색을 수행할 수 있다.
- 사이트 전체를 데이터베이스에 저장해 두고, 여러 가지 분석을 수행할 수 있다.
- 링크를 따라다니며 다운로드하기
- 자신이 운영하지 않는 웹 서버에 FTP 등으로 접속해서 파일을 모두 다운로드 할 순 없다.
- 그러니 페이지의 링크 정보를 바탕으로 HTML을 순회하며 한 페이지씩 내려받아야 한다.
- 프로그램
- 3단계까지 링크를 타고 들어가서 HTML을 다운로드하는 프로그램 작성
- Node.js의 한글 문서 페이지를 한 번에 다운로드 하는 프로그램 작성
- LINK_LEVEL 상수 : 몇 단계까지 링크를 탐색할 지 나타내는 상수
- 코드
// doownloading modules
const client = require('cheerio-httpcli');
const request = require('request');
const urlType = require('url');
const fs = require('fs');
const path = require('path');
// common config
// config link search level
const LINK_LEVEL = 3
// stanaard url page path
const TARGET_URL = "http://nodejs.org/dist/latest-v14.x/docs/api/";
let list = {};
// main process
downloadRec(TARGET_URL, 0);
function downloadRec(url, level) {
// confirm MAX_LEVEL
if(level >= LINK_LEVEL) return;
// Ignore downloaded pages
if(list[url]) return;
list[url] = true;
// Ignore external pages
let us = TARGET_URL.split("/");
us.pop();
let base = us.join("/");
if(url.indexOf(base) < 0) return;
// get HTML
client.fetch(url, {}, function(err, $, res){
// get linked pages
$("a").each(function(idx){
// get "<a> tag" links
let href = $(this).attr('href');
if(!href) return;
// convert relative path to absoulte path
href = urlType.resolve(url, href);
// Ignoreing after '#' character, equal a.html#aa and a.html#bb
href = href.replace(/\#.+$/, ""); // delete a '#' from end of line.
downloadRec(href, level +1);
});
// save pages(assign file names)
if(url.substr(url.length-1, 1)=='/') {
url += "index.html" // add index automatically
}
let savepath = url.split("/").slice(2).join("/");
checkSaveDir(savepath);
console.log(savepath);
fs.writeFileSync(savepath, $.html());
});
}
// confirm whether exesting to save directory.
function checkSaveDir(fname) {
// detech only directory part
let dir = path.dirname(fname);
// create diretory recursivly
let dirList = dir.split("/");
let p = "";
for(let i in dirList) {
p += dirList[i] + "/";
if(!fs.existsSync(p)) {
fs.mkdirSync(p);
}
}
}
- 결과
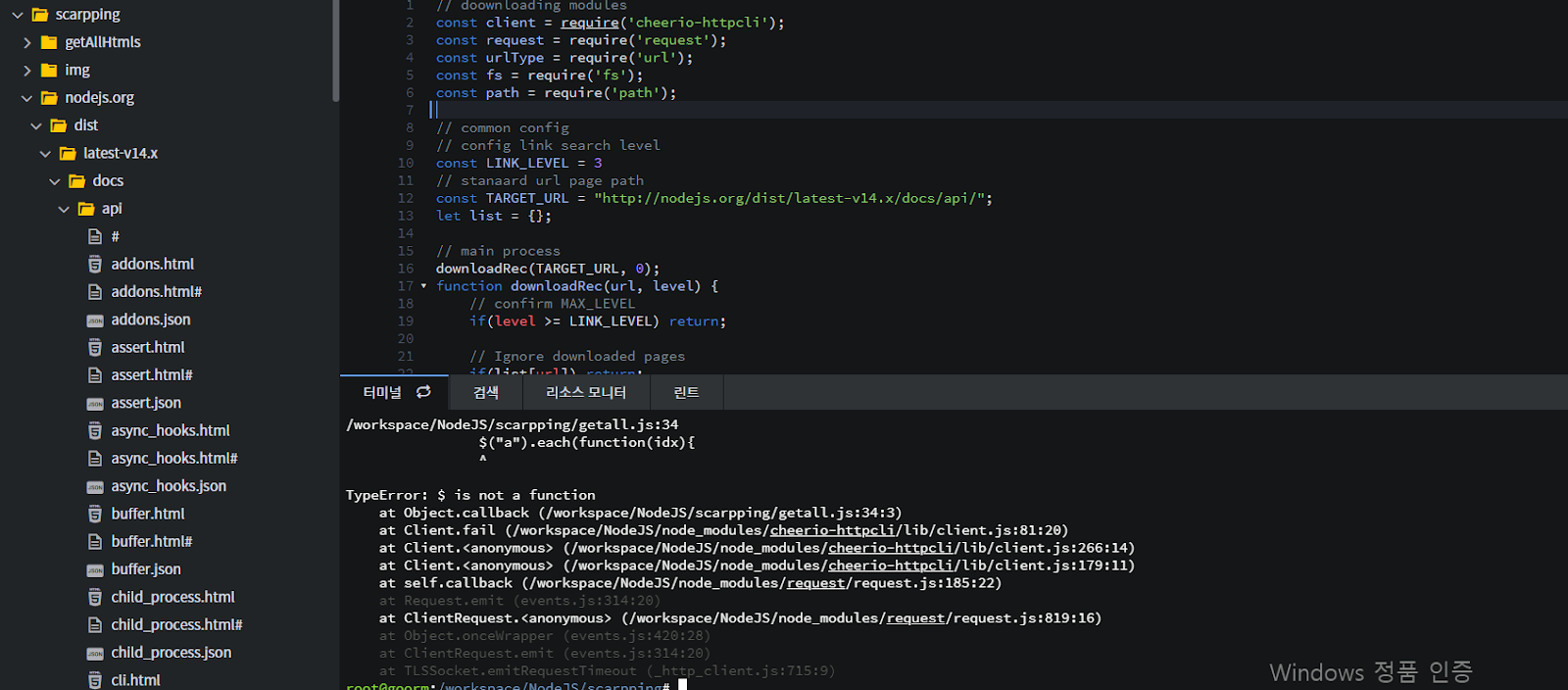
- 연결된 HTML을 계속하여 다운로드받는 재귀적 프로그램의 대표적인 예로 볼 수 있다.
- 함수의 반복 처리 내용
- 방문 레벨 검사, 최대 레벨을 넘어선 경우에는 함수를 벗어나도록 해야한다.
- 이미 다운로드한 URL인 경우 함수를 벗어나야한다.
- URL의 HTML을 획득한다.
- HTML에서 태그를 빼내고, 다음을 되풀이한다.
- 링크 정보(href) 속성을 꺼내서 절대 패스로 변환한다.
- href 속성 값을 인자로 downloadRec()를 호출한다.
- HTML을 로컬에 저장한다.
- 재귀 처리를 쓸 때 주의할 점
- 재귀 처리에서 함수 안에서 그 함수 자신을 처리하기 때문에 무한히 반복 할 수 있다.
- 이 때문에 함수 호출 레벨을 확인하고 최대 레벨을 초과하면 벗어나는 조건을 추가해야 한다.
- 동일한 URL을 반복분석 하지 않도록 중복 체크를 해주어야 한다.