Introduction
부족하지만 웹이나 SNS 상의 데이터를 크롤링하여 얻어온 데이터를 감성분석하여 키워드에 대한 사람들의 감정을 알아보려는 프로젝트를 기획하고 있다.
이 글은 데이터를 웹으로부터 얻어오기 위한 첫 기록이며, 내가 공부하는 책의 Summary이다.
Jpub/JSWebCrawler
<자바스크립트와 Node.js를 이용한 웹 크롤링 테크닉> 리포지토리. Contribute to Jpub/JSWebCrawler development by creating an account on GitHub.
github.com
ECMAScript가 실현한 범용 자바스크립트의 세계
- ECMAScript는 Ecma International에 의해 표준화된 스크립트 언어의 명세서.
- 웹 브라우저별로 달랐던 클라이언트 기반 스크립트의 구현을 표준화시키기 위해 탄생
- 자바스크립트는 웹 브라우저의 제약을 뛰어넘어 다양한 애플리케이션에서 매크로 언어로도 사용
- CC(Createive Cloud) Adobe 시리즈 제품들이 자바스크립트를 이용해 각종 자동화를 수행.
- Windows에서는 기본적으로 JScript 엔진이 탑재.
- HTML덕분에 스마트폰 애플리케이션에서도 자바스크립트로 개발이 가능.
- PhoneGap 프레임워크처럼 HTML 만든 웹 애플리케이션을 네이티브 애플리케이션으로 변환하는 기술이
발전 하여 성능상의 문제도 없다.
자바스크립트 엔진의 이모저모
- 웹 브라우저에서의 자바스크립트 엔진 --> 웹 브라우저를 의존하지 않고 다양하게 이용 가능한
자바스크립트 엔진으로 변모
- 고속 엔진에서 탄생한 Node.js
- Node.js는 웹 서버처럼 네트워크 프로그래밍을 위해 개발된 자바스크립트 환경
- Node.js의 Core는 Google Chrome에 탑재된 JavaScript Engine V8
- V8의 가장 큰 특징
- 고속 수행 능력 :
웹 브라우저의 자바스크립트가 보안 때문에 파일 처리 등이 불가능한 것에 반해
Node.js를 사용하면 파일부터 네트워크 처리까지 다양한 작업을 소화
- Node.js는 서버에서 실행되는 자바스크립트 실행 환경(런타임)으로 많이 활용
- 자바의 풍부한 자산을 이용 가능한 Rhino와 Nashorn
- Rhino와 Nashorn
- 이들 자바스크립트 엔진은 자바로 구현되어서 JVM(Java Virtual Machine)위에서 구동 가능.
- 이들 엔진의 최대 장점 : 자바스크립트로 자바의 기능에 접근 가능한 것.
- Rhino는 자바 1.4 이후에서, Nashorn은 최신 자바 SE8 이후에서 이용 가능.
- 기본적인 기능은 같으나 Nashorn은 최신 자바 버전에 맞게 다시 작성되어서 JVM의 새로운 기능을
고속 수행이 가능하다.
- 또한, 에러 메시지가 친절하게 나와 디버깅이 쉽다는 특징이 있다.
- Windows에 표준으로 탑재된 JScript
- 윈도우에서만 이용 가능한 단점이 있으나, 윈도우에 특화된 다양한 기능을 다룰 수 있는 장점
- JScript를 이용하면 윈도우의 ActiveX(COM) 기술에 대응한 각종 애플리케이션의 기능 사용 가능
- 예를 들어, 엑셀에 있는 명부를 워드로 만든 편지 서식의 수신인에 끼워넣는 것처럼 실무에 편리한
기능을 쉽게 이용 가능
- 'JScript Execel'등의 키워드로 검색하면 엑셀을 좀 더 잘 활용하기 위한 다양한 팁이 검색
- 자바스크립트가 데이터 수집에 적합한 이유
- 코드 작성이 쉽다 : 많은 웹 페지에서 자바스크립트가 이용되고 있는 만큼, 데이터 수집을 위한 자바스크립트 코드를 쉽게 작성 가능
- 배우기 쉽다 : 자바스크립트의 기본적인 문법은 간단하다 (하지만 구조를 파보면 마냥 쉽지는 않다)
- 다양한 라이브러리가 준비되어 있다 : 대중성이 높은만큼 다양한 자바스크립트 실행 엔진이 존재하고,
이를 통해 다양한 라이브러리를 쉽게 사용할 수 있다
- 유연성이 높아 코드를 빠르게 작성할 수 있다 :
Interpreter 방식으로 코드를 해석하는 언어들이 그렇듯, 프로그램을 작성할 때 변수의 타입을 지정하지
않거나, 클래스의 구조를 쉽게 변경가능한 프로토타입 기반의 객체지향적인 코드를 유연성이 매우 높게
작성 가능하다. Node.js의 경우에는 모듈 단위로 관리 가능(유연성이 높은만큼, 코드에 대한 개발자의
유의가 필요하다.)
에이전트의 의미
- Agent란 타인이나 타 조직이 의뢰를 받고 대신 해동해주는 개인이나 조직을 뜻한다.
- 작업, 처리, 업무를 IT 분야에 적용한 것 : 소프트웨어 에이전트
- 사용자 혹은 다른 소프트웨어를 대신하여 다양한 작업을 수행해 주는 프로그램
- 웹 사이트로부터 다양한 데이터를 수집하고, 일련의 처리를 자동으로 수행해주는 에이전트
- 지능형 에이전트
- 인공지능으로 사용자를 돕고, 반복되는 작업을 사용자 대신하여 처리
- 지능형 에이전트의 특성
- 환경과의 상호작용을 통해 학습하며 동작이 개선
- 온라인으로 실시간 적용, 대용량 데이터를 고속으로 학습
- 새로운 문제 해결 규칙에 적응
- 자신의 동작에 대해 성공과 실패를 스스로 분선
- 바이어 에이전트
- 구매 봇, 아마존에서 쇼핑할 때 페이지 및 유사 상품들이 표시되고 이것은 그 페이지를 본 다른
사용자가 구매한 상품이나 사용자가 본 다른 상품의 경향 정보를 이용한 것
- 사용자의 취향을 고려해서 상품을 추천
- 감시자 에이전트
- 웹 브라우저나 이메일 클라이언트의 경우 사용자를 위해 자동으로 작업을 수행.
- 웹 브라우저는 사용자와 웹 서버 사이에서 정보를 주고받는 에이전트. 사용자가 보고 싶은 페이지를
웹 브라우저에 입력하면 웹 브라우저가 서버의 데이터를 보기 쉬운 형태로 표시
- 보다 고도의 에이전트의 경우 사용자의 취향에 맞게 웹의 뉴스를 모으는 일도 수행
- 데이터 마이닝 에이전트
- 데이터 마이닝 : 크고 다양한 데이터로부터 유용한 정보를 발굴하는 것.
- 데이터 마이닝 에이전트는 정보를 수집하고 모은 데이털틀 분류, 분석 한다.
- 그리고 트렌드의 전환을 검출하거나 새로운 정보를 찾아낸다.
개발환경 구축
- 프로그램을 개발할 때 가상 환경을 구축해 높으면 편리한 점이 많고, 실제로 책에서는 가상 환경에 Cent OS
설치하여 사용하였으나 나의 경우는 goormIDE를 사용해서 진행할 것이다.
- goormIDE의 전반적인 사용법은 이 글에서는 적지 않을 것이다.
- goormIDE에서 대시보드를 이용하여 Node.js를 선택한 후 새 프로젝트를 생성한다.
- 터미널에 suvisudo를 터미널에 입력한다.
Defaults env_reset -> Eefaults !env_reset
Defaults env_keep += "HOME" # 추가
#Defaults secure_path =/... # 주석처리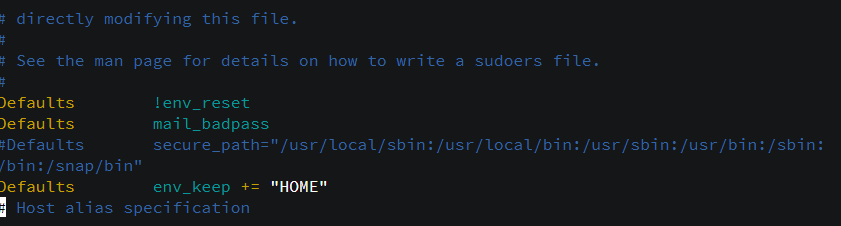
- 이제 패키지 인스톨을 위한 yum을 설치한다.
- YUM은 외부 리포지토리 서버랑 통신이 가능해야 하지만, 구성 요소들을 웹에서 다운받아와서
의존성 문제를 해결해 준다.
- 설치 : apt-get install -y yum
- 사용법 :
- RPM 파일 설치 : yum install [*.rpm 파일 이름]
- 업데이트 가능 목록 보기 : yum check-update
- 업데이트 : yum update [패키지이름]
* 패키지 이름을 입력하지 않으면 전부 다 업데이트 한다.
- 삭제 : yum remove [패키지 이름]
- 고급 사용법 :
- 패키지 그룹 설치 : yum groupinstall "[패키지 그룹 이름]"
- 패키지 리스트 확인 : yum list [패키지 이름]
- 특정 파일이 속한 패키지 이름 확인 : yum provides [파일 이름]
- YUM 설정 파일 :
- /etc/yum.conf(파일) : 변경할 필요 없다.
- /etc/yum.reps.d/(디렉토리) : yum 명령을 입력했을 때 검색하게 되는 네트워크 주소가 포함.
- git은 이미 goormIDE container에 설치되어 있지만 만약 필요하다면 : sudo yum install git
- NPM 모듈 설치
- NPM : Node.js의 모듈을 관리하는 패키지 관리자 (Node Package Manager)
- YARN과 NPM을 비교한 글
https://medium.com/@ehddnjs8989/npm-vs-yarn-3a611c89d291
Npm vs Yarn
Package manager를 선택을 고민하시는 분들은 한번 읽어보시면 좋을 것 같습니다.
medium.com
- 간단히 요약하자면, 성능보다는 보안성에 주목한다면 YARN을 사용.
- npm은 패키지가 설치될 때 자동으로 코드와 의존성을 실행할 수 있도록 허용했지만 안정성
측면에서 위험도가 증가하였다. 특히 정책 없이 등록하였던 패키지 제출문 부분에서 위험도가 높음
- yarn은 yarn.lock이나 package.json으로부터 설치만 한다. yarn.lock은 모든 디바이스에 같은 패키지
를 설치하는 것을 보장하여 다른 버전을 설치하는 것으로 오는 버그 발생률을 줄였다.
- 사용자와 다운로드 점유율이 높은 npm을 사용하거나 안정적인 yarn을 사용하는 것은 사용자의 선호
- 나는 익숙한 npm을 사용할 것이다.
- npm install로 모듈 설치
- 웹 사이트로부터 파일이나 데이터를 내려받을 때 사용하는 request 모듈 설치 : npm install request
- * npm install을 실행하면 그 모듈에서 사용하는 다른 모듈(의존 모듈)도 같이 설치된다.
- request를 사용하기 위해 mime-type 모듈과 form-data 모듈을 따로 설치하지 않아도 된다.
- 모듈이 설치되는 경로
- npm install로 모듈을 설치하면 이 명령을 실행한 현지 디렉토리에 모듈이 다운로드 된다.
- 정확하게는 현재 디렉토리에 node_modules라는 디렉토리가 만들어지고, 그 안에 모듈이 다운로드 된다.
- 모듈을 설치했어도 다른 디렉토리에 배치된 프로젝트에서는 그 모듈에 접근할 수 없다.
- global 설치 -g
- 모든 프로젝트 및 폴더에서 사용하고 싶다면 모듈을 설치할 때 -g 옵션을 붙이면 글로벌한 경로에 모듈이 설치
- 사용 : npm install -g (모듈 이름)
- 권한이 필요할 때 : sudo npm install -g (모듈 이름) # 관리자 권한으로 명령 실행
- global 설치시에 PATH에 주의
- npm을 통해 모듈을 글로벌하게 설치하면 linux운영체제의 경우 /usr/lib/node_modules에 설치
- npm으로 글로벌하게 설치한 모듈을 Node.js가 찾을 수 없는 경우, Node.js가 모듈을 찾을 때 어떤
경로를 검색하는 가를 확인해야 한다.

- node -e "console.log(global(module.paths)"
- 현재 작업 디렉토리인 node_modules를 차례대로 검색한다는 사실을 알 수 있다.
- 이와 별개로 Node.js는 환경 변수 NODE_PATH에 저장된 경로도 검색한다.

- 혹시나하고 NODE_PATH 환경변수가 있는지 확인해 보았지만 존재하지 않는다. 추가하자

- 나중에 모듈을 살제할 때 : npm uninstall (모듈 이름)
웹 페이지 다운로드
- 가장 간단한 다운로드 방법
- 웹 브라우저에서 현재 보고 있는 페이지를 자신의 PC에 저장.
- 대부분의 웹 브라우저는 HTML 파일 하나만 내려받지 않고 그 안에 연결된 이미지나 CSS 파일들을
다운로드 한다.
- Node.js 로 다운로드
- 코드
const http = require('http'); // HTTP 모듈
const fs = require('fs'); // 파일 처리 관련 모듈
//url : 다운로드 할 url 지정
//dest : 저장할 위치를 지정
function downloadHTML(url, dest) {
const outfile = fs.createWriteStream(dest);
// 비동기로 URL의 파일 다운로드
http.get(url, function(res){
res.pipe(outfile);
res.on('end', function(){
outfile.close();
console.log("done");
});
});
};
function main(){
console.log("Hello goorm!");
let url = "http://jpub.tistory.com/";
let dest = "test.html";
downloadHTML(url, dest);
}
main();
- 결과
- 위의 프로그램에서 사용하는 모듈은 require을 통해 로드하고 있다.
- fs.createWriteStream() 메소드로 저장할 파일 이름을 지정하고, http.get() 메소드로 URL에 접속한다.
- http.get() 메소드의 반환 값이 우리가 획득하려는 데이터가 아니다.
- Node.js에서는 시간이 걸리는 처리를 비동기적으로 수행하는 스타일을 수행한다.
- 수행이 끝날 때까지 진행을 멈추고 기다리는 대신, 처리가 완료되었을 때 콜백 함수가 호출되는 식
- 서버에 요청만 보내고 수행 흐름이 계속된다.
- 우리가 원하는 데이터는 http.get() 메소드의 두 번째 인자로 지정한 콜백 함수에 전해지고
- 콜백함수에서는 다운로드한 데이터를 파일에 저장하도록 지정한다. (여기서도 지정만 할 뿐,
이 시점에서 저장이 완료되는 것은 아니다.)
- 서버로부터 response를 받는 데에도 시간이 걸리므로 처리가 완료되었을 때 콜백 함수가 호출된다.
- 다운로드가 완료되면 end에 지정한 함수가 호출된다.
- 코드 리팩토링
- 함수를 사용해서 코드 재사용성을 높여보았다.
function download(url, savepath, callback) {
const http = require('http');
const fs = require('fs');
const outfile = fs.createWriteStream(savepath);
let req = http.get(url, function(res) {
res.pipe(outfile);
res.on('end', function(){
outfile.close();
callback();
});
});
};
download("http://jpub.tistroy.com/539",
"spring.html",
function(){console.log("ok, spring.")});
download("http://jpub.tistroy.com/537",
"angular.html",
function(){console.log("ok, angular.")});
- Rhino / Nashorn으로 다운로드 해보기
- 자바로 만들어진 자바스크립트 엔진들로 구현해보자.
let url = "http://jpub.tistory.com/";
let savepath = "test.html";
// Download
let aUrl = new java.net.URL(url);
let conn = aUrl.openConnection(); // URL에 접속
let ins = conn.getInputStream(); // 입력 스트림을 획득
let file = new.java.io.File(savePath); // 출력 스트림을 획득
let out = new.java.io.FileOutputStream(file);
// 입력 스틀미을 읽으면서 출력스트림에 쓴다.
let b;
while((b=ins.read()) != -1) {
out.write(b);
}
out.close();
ins.close();
- 실행 : rhino mainUsingRhino.js
- Nashorn의 실행 : jjs mainUsingRhino.js
- 위 프로그램의 핵심은 자바 API를 사용한다는 것에 있다. 자바 API를 그대로 사용한다는 것이 장점이다.
- 자바의 파일이나 네트워크 API는 데이터를 스트림으로 다룬다.
HTML 해석
- 웹페이지를 다운로드하면, 그 페이지를 해석해야 한다. HTML에 링크된 URI나 이미지 파일 등이 이용가치가 높다.
- 스크래핑
- 웹 사이트에서 HTML 데이터를 수집하고, 특정 데이터를 추출, 가공하여 저장하는 것
- 단순히 웹 사이트에서 HTML 파일을 다운로드만 하는 것이 아니라 그 HTML 파일의 각 요소들을
분석하는 과정을 포함한다.
- cheerio-httpcli 모듈 설치
- Node.js를 사용하여 스크래핑 할 때 편리한 모듈이다. 손쉽게 HTML 파일들을 다운로드 가능하고
jQuery와 비슷하게 요소를 획득할 수 있다.
- 웹 페이지의 문자 코드도 자동으로 판정하여 읽어 준다.
- 페이지 안의 데이터를 꺼낼 때 간편하게 지정한 요소를 추출할 수 있는 점이 가장 큰 장점이다.
- 다운로드 : npm install cheerio-httpcli
- 코드
const client = require('cheerio-httpcli');
const url = "http://jpub.tistory.com";
let param = {};
client.fetch(url, param, function(err, $, res){
if(err) {console.log("Error:", err); return;}
let body = $.html();
console.log(body);
});
- 결과
- request 모듈을 사용한 프로그램보다 더 쉬워졌다. fetch() 메소드 하나로 다운로드부터 페이지의
해석까지 완료되었다.
- 다운로드(HTML을 취득)하는 부분에서 fetch() 메소드를 사용하고 인자로 URL, 파라미터, 콜백함수의
순서로 지정한다. 이 콜백 함수는 웹 사이트에서 데이터의 취득이 완료된 시점에서 실행된다.
- 콜백함수의 인자 : 오류 정보(err), 취득한 데이터($), 서버의 응답 정보(res)
- 프로그램에서 취득한 데이터를 담은 변수 $의 html() 메소드를 호출함으로써 취득할 HTML을 화면에
표시했다.
- HTML 파일에서 링크 추출
- 'cheerio-httpcli' 모듈은 웹에서 HTML 파일을 내려받은 뒤 CSS 선택자를 통해 임의의 요소를 추출
하는데 사용한다.
- 이번에는 HTML에 링크된 URL 목록을 출력하는 프로그램을 만들어 보자.
- 코드
const client = require('cheerio-httpcli');
let url = "http://jpub.tistory.com";
let param = {};
client.fetch(url, param, function(err, $, res) {
if(err) {console.log("error"); return;}
$("a").each(function(idx) {
let text = $(this).text();
let href = $(this).attr('href');
console.log(`${text}:${href}`);
});
});
- 결과
